

Introduction

Despite we think this was a remarkable achievement, there was still a big limitation: the port only supported the shareware levels. This limitation did not go unnoticed, and we got some feedback about not providing the full retail game support.
In the original article, we briefly mentioned the issues about supporting the retail version, but we will now elaborate on them in more detail.
- Retail maps have more entities, and, in particular, more enemies, which consume a lot of RAM.
When we started our porting journey, we checked online sources (https://quakewiki.org/ and https://quake.fandom.com/) to see how many enemies were present on each level, including retail ones. We found that some of the retail levels contained far too many enemies. Specifically, on the nightmare and hard skill levels, E4M3 features 105 monsters, whereas E1M3 (the map with the highest number of enemies in the shareware episode) has only 65 of them at the hardest skill setting. As a result, we determined that we needed at least 8 kB additional RAM in the zone memory (in our implementation, entities are dynamically allocated, unlike in the original Quake implementation). Actually, we needed 9kB more, because E4M3 has also more other kinds of entities such as triggers/doors, not counted in the online sources. - Retail maps have more complex geometries, i.e. they have a larger number of vertices, edges, etc.
Map complexity impacts both RAM and internal flash usage. Let’s first talk about RAM.
In the last article, we wrote that we have trimmed some static limits – such as number of nodes, etc. – to save on memory while still being able to play all the shareware levels. This means that some retail levels could not fit with this configuration. For instance, the maximum number of edges was limited to 14800, whereas retail levels have up to about 17000 of them. Surfaces were also limited to 6144 in total, but in retail maps, the number of surfaces can go up to about 7100.
Increased map complexity does not affect only RAM usage, but also precious internal flash usage. In fact, we cache all the current level geometry data (vertices, edges, faces, etc.) to the internal flash, because these are accessed very frequently. Reading them from external flash would be dramatically slow, because such geometry data are rather large, and they are not accessed sequentially.
In our first release, the internal flash had barely enough space to store the data of the most complex map of the shareware episode (E1M4). Retails levels required more space, which was not available. - The retail version of Quake has more types of enemies.
Similarly to what we do for the world model (the map), we also partially store some data of “alias models” in the internal flash. This means that even more internal flash was needed to support the additional types of monsters. - We had removed multi-PAK file support.
The shareware Quake just needed PAK0.PAK, so we removed any code related to handling more than one PAK file. Retail data is stored in PAK1.PAK so to play the full game, the code had to be able to read data in both in PAK0.PAK and in PAK1.PAK. - The Gamepad we built used two 16-MB flash ICs. However, even the PAK1.PAK alone is larger than that amount.
There are two reasons for which we used two 16-MB flash ICs.
- We intended to support only the shareware version. So, 32 MB is more than enough to store PAK0.PAK which originally is 18 MB, but it grows to about 23 MB when it is converted by our tool.
- We could easily find breakout boards supporting only 16 MB flash ICs. For larger sizes, one has to buy separately SMD chips and a SOIC to DIP breakout board, e.g. from Sparkfun (https://www.sparkfun.com/products/13655), while our goal was to keep The Gamepad a through hole only project.
Despite these good reasons, we thought we released an unfinished work.
Completing an unfinished work
This time our challenge is to support the full retail version. In particular:
- Supporting the retail level shall only minimally affect the performance we got previously, on the shareware levels. In particular, we wanted to keep a frame rate on the shareware 8 + 1 levels closer to what we got in our first release.
- All the shareware + retail levels at the hardest skill shall run.
- Still no external RAM can be added.
This is what was admitted:
- Still no limit on the external flash IC. We already know we will have to increase its size.
- Still no need to support multiplayer, music and demo recording.
- Still using the default resolution (320×200 pixel, with default status bar height).
- Still no music support.
Hardware Fixes
As we mentioned, to support the full data pack, we need more than 32 MB flash. Yes, we could try to optimize/compress data as Kilograham did for his Doom port on the RP2040 (where the full WAD could fit an 8MB flash), but this was outside the scope of our project. In fact, our MCU has just enough computing power to run a playable Quake port, and everything else it is added would decrease performance. Keeping a similar performance achieved on the previous article was amongst the requirements. Also, adding decompression routines might increase flash usage due to additional code.
Unfortunately, as we said before, we could not find any 8-DIP breakout boards featuring SPI flash ICs larger than 16 MB (W25Q128). Therefore, we bought the previously mentioned SOIC to DIP converters, and soldered there two BY25Q256FSSIG ICs.


Yes, you might also go hardcore, and mount a W25Q256 IC in WSON8 package as well:
- Cut a piece of prototyping board, so that it will have 4×4 holes.

- Solder two 4-pin headers.
- Attach some Kapton tape (which can withstand high temperatures) on the back of the flash IC, to isolate the exposed pad and prevent short.
- With a cutter, trim the excess Kapton so that only the exposed pad is covered.

- Use double-sided tape to mount in dead-bug style the IC on the small board. Alternatively you might try hot-glue.
- With some thin wire, connect the headers to the flash IC pads. We suggest first soldering the wire to the header pad, and then soldering to the IC pad.
- Repeat previous step for the second flash.

Software Modifications
First, to solve the issue of multiple PAK files support, we decided to modify the MCUPackfileConverter tool we developed. Now it will look for PAK0.PAK and PAK1.PAK and if the latter is found as well, a single big PAK0conv.PAK is created. This converted file contains all the files stored in PAK0 and PAK1. We used this solution, as opposed to implementing multi-pak file support, because this would increase code complexity on the MCU side, without bringing any benefit.
Secondly, and most importantly, we had to address both RAM and flash usage.
Optimizing Flash
By compiling our port on WIN32 (where we can set any amount of emulated internal flash, so that level loading won’t fail), and checking all the levels, we found that on the level E4M7 was short of 72 kB flash.
We acted in two ways:
- Reducing the code size (i.e. the binary of the compiled project)
- Reducing the data stored in internal flash (i.e. what we are caching to the flash).
Let’s described what we have done.
The majority of our source was optimized for speed. Moreover, for some sources, we use the -mslow-flash-data compilation flag, to instruct the compiler to use one or two MOV instructions, instead of loading a 32-bit constant from flash. This is because while the EFR32xG24 SoC has an instruction cache, any data loaded from flash does not pass through the cache system, incurring to wait states penalty, even if such data is present on the instruction cache line. This means that with such flag, the code typically grows in size, but it gets faster.
On selected files, we have turned off the optimize for speed (-Ofast), settings the optimize for speed flag (-Os) instead, as well as removing the -mslow-flash-data flag. Also, we enabled on some files the link-time optimization, which allowed for some more savings. The savings was about 51kB: a very remarkable step, but still not enough for E3M5 and E4M7.
To gain few the remaining 21 kB:
- We removed the debug messages in the EFR32MG24 application. This allowed us to gain about 5 kB.
- We realized that the surfNodeIndex array we created to handle dynamic lighting could have been embedded into the model surfaces array (both of them are stored in the internal flash). In fact, we forgot that in the msurface_t structure, we had intentionally left 16 bits unused in order to create a 32-byte structure (instead of 30 bytes). We simply overlooked the possibility of storing each element of surfNodeIndex (which is intended to retrieve the node index of the surface) in that space. This allowed to save about 14 kB on E4M7.
- Models were using a pointer to a string, to identify their name. Such string was stored to internal flash. The model name is important because this is used by the server and client to identify which model is/should be cached. However, since the name is a string which is already assigned to an index, we realized we could store the index instead, as opposed to the full name. This saves some kB of data.
- We have removed some code which is not used, but it is still not optimized out, because it is referenced into some structures, or in some switch-case statements (despite that case never being actually hit). Such code belongs to multiplayer (including some multiplayer options) and profiling/benchmarking. We also have removed some unused Cvars declaration.
Optimizing RAM
As we said, the bigger maps also impacted on RAM usage. In particular, the larger number of entities (and in particular, monsters) required a larger amount of zone memory, and the larger number of edges (about 17000 instead of 14800) required to increase the region where we temporarily store the cached edge offsets.
(you can skip this section if you don’t need/want to understand what are the cached edge offsets used for)
At this point one parenthesis is worthwhile: what it the purpose of the cached edge offset?
The software rendering of the world model is divided in many steps.
First the renderer finds the list of potentially visible surfaces, i.e. not including those which are for sure not visible, being either blocked by other surfaces, or because outside of your view volume, e.g. behind you.
This list of potentially visible surfaces, however, includes partially visible ones, which might be almost completely covered by other ones.
Thanks to the BSP structure, when filling such list, the surfaces are traversed front to back. Therefore, an index can be associated to each found potentially visible surface, so that, given two surfaces we can already know which is closer.
Therefore, one might think that the surfaces can be simply drawn using a back to front drawing algorithm. This would give the correct 3D rendering, but at a high price: overdraw. In fact, even if only one pixel is visible on one surface, with this naïve method one shall draw completely the bottom surface. This would tremendously slow down the rendering.
To prevent overdraw, the software renderer takes additional steps. Quake uses an edge-based rendering technique, which will create a list of edges belonging to the topmost visible surfaces of the current frame. The information of the edges of such list are stored in an array in stack (r_edges). As two contiguous surfaces might share one edge, Quake reuses (caches) such edge. This allows to:
- Reduce the number of edges in the list. This on one hand allows using less stack, on the other, it speeds up rendering by iterating on a smaller amount of data.
- Reduce the number of clipping operations required, further speeding up rendering.
To implement this caching mechanism, for each model edge we need to know if the edge was cached and where it is the r_edge array. In Quake, this was accomplished storing the memory offset in the edge structure of the model itself (the actual implementation is a little bit different, but this is not important for this explanation). In our case, the model’s edges are in flash, so we must store such offsets in a separate array, where each element belongs to each model edge. Each element is 16 bits, because they are enough to store the index of the element of the r_edge array. More precisely, what we store is not actually the index in r_edge, but the index in base_edge_p, which is a pointer that starts one element earlier than r_edge. This allows to use the value 0 to indicate “edge not cached”. This is useful to quickly invalidating the cached edge offset array each frame, by zeroizing it.
This is not the end of the rendering process, which requires additional steps. However, such information is irrelevant to the cached edge offset we wanted to introduce.
As you might remember from the previous article, in our port we reuse extensively the texture cache buffer and the Z-buffer. We identified the texture cache buffer as a good candidate to store the cached edge offset array, as initially it was quite large [1](>30k).
It was trimmed down to 29600 so that it could be still used to hold the cached edge offsets for any shareware map, while allowing to gain few more bytes for stack or zone memory.
Reducing the size of the texture cache buffer may affect performance because, if it is too small, only one texture can be held at the same time, therefore we will be unable to take advantage of the asynchronous texture load with DMA, which occurs when the CPU is rendering.
However, we later verified that the texture cache buffer could be even smaller without impacting too much on the performance, because typically the combination of texture sizes to be stored is 4kB+4kB, 8kB+8kB or 16kB + 4kB. When a larger amount is required (e.g. when we are rendering a surface using a 16 kB texture, and the next different texture to be used will be 16 kB as well) a penalty will occur, but this event is quite rare, and still the rendering will not fail. This means that if we need some memory, we can reduce even further the texture cache buffer size, down to 20kB, without any measurable impact.
Now, on one hand we would like to reduce the texture cache buffer to 20kB, so that we increase the Zone memory to accommodate the larger amount of entities. On the other hand, we need to increase the texture cache buffer, because we are temporarily storing there the cache edge offsets, whose number has increased in the retail version: two opposing constraints.
To solve this, we found that we have some more unused space available in the Z-buffer before rendering. Therefore, the first edges are stored into the texture cache buffer, and those that do not fit are temporarily stored in the Z-buffer. The cached edge indexes are not used anymore, as soon as we actually start drawing.
Having ascertained that 20kB are enough for the texture cache buffer to keep a decent performance, we used that size (instead of the old 29600-byte size), to gain 9kB for the zone memory.
Impact on performance
Optimizing some files for size instead of speed could reasonably have some impact on performance. However, we initially found that the timedemo score dropped by only 0.1 fps (from 28.0 to 27.9 fps), and on the average live game, the frame rate decreased by about 0.1-0.5 fps. The larger drop was due to the server code being optimized for size instead of speed. Server code is not executed in the timedemo benchmark.
However, after having analyzed the memory consumption, both in terms of RAM and internal flash, we found some nice surprises…
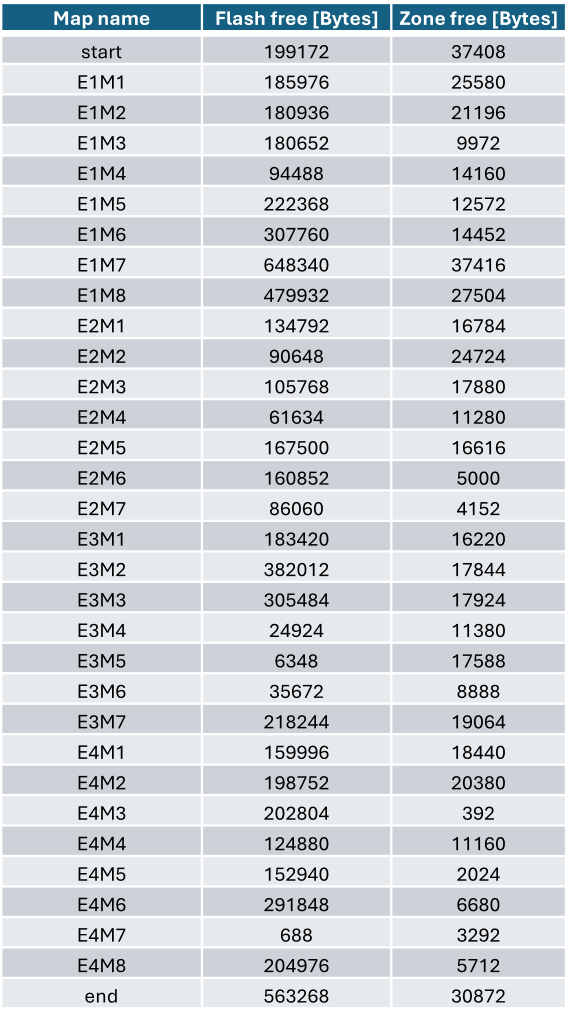
In fact, as shown in the table below, in many levels, especially shareware ones, we had “a lot” of flash and RAM available after the level is loaded. There was room for improvement now.
More room for improvement
Every level in Quake is different. Some of them feature more complex geometries, some have more enemies/objects. Sometimes we have both complex maps and many entities, sometimes we have very small maps with few entities. This means that the actual internal flash and RAM usages differ from level to level, and for some levels (including some retail ones) we have an excess of unused RAM and/or flash.
In some cases, the amount of available RAM/internal flash is very large, i.e. even 20kB of zone memory, and hundreds of kB of internal flash.
If memory can be used to improve speed, and we don’t use it, it means we are not doing the right thing. However, choosing what actually we should cache is not a trivial task.
We decided to cache some model’s skins to internal flash, and, whenever the free zone memory exceeds 20 kB, we copy the full colormap to RAM.
The speed increment is not dramatic, but it was “free”.
For instance, we verified that if we copy the colormap to RAM (16 kB), we gain about 800 microseconds. This is consistent with the additional 2 wait states we incur by loading a byte from flash instead of RAM. When running at 20 fps when the colormap is in internal flash, however, saving 800 us does not give appreciable increase in the framerate, which increases to only 20.3. The situation is more remarkable when running at 30 fps, where the gain is 0.7 fps. Still, despite improvement is not noticeable during in-game play, it allows to overcome the loss of performance we incurred in compiling some files with size – rather than speed – optimization.
A much larger improvement can be achieved if we have enough internal flash left. Each level has its different sets of enemies, objects and even weapons. For instance, just caching the most used weapons of each level will give a noticeable performance increase. If there is also space for caching the most frequently encountered enemy, then the speed increase is even higher.
For instance, the timedemo performance has increased to 29.2 fps (it was 28.0 fps, and decreased to 27.9 after adding support for the retail version). The E1M1, which had a framerate around 26-27 fps, now has an initial framerate of 27-28, i.e. 1 fps higher.
To quantify the speed improvement, we show below the instantaneous timedemo frame rate of the demo 3, together with what we achieved last time.
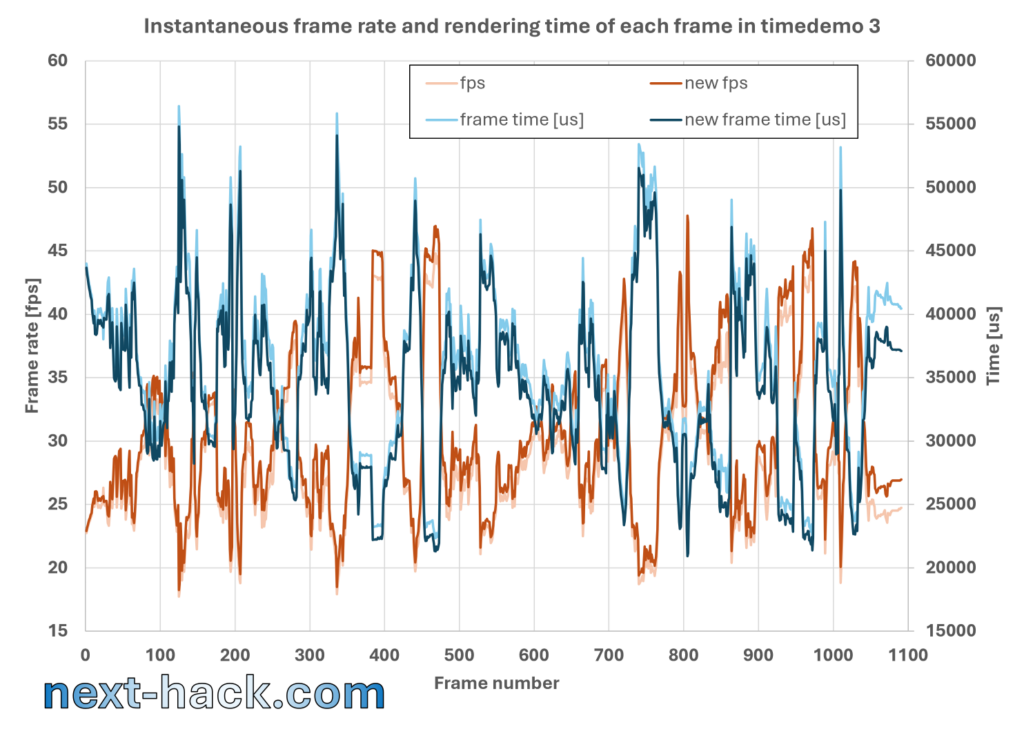
We also show the comparison between the old and new framerates at the beginning of the “start” and “E1M1” maps.

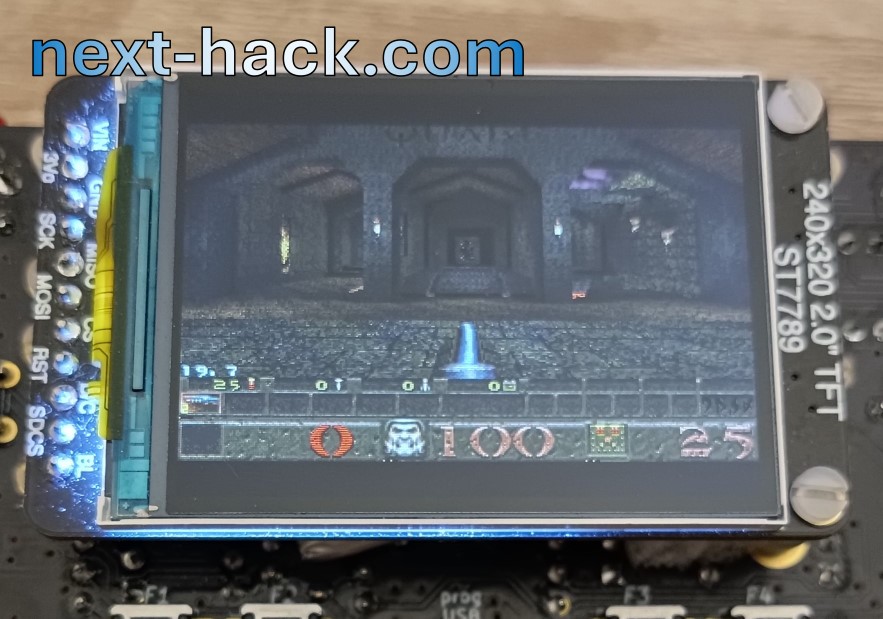

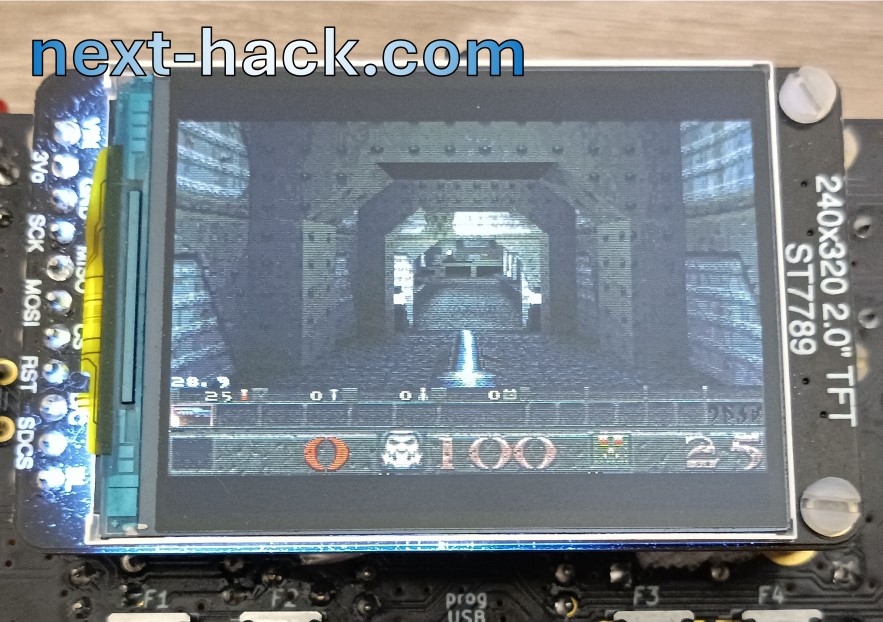
Some pictures of retail maps








Github repository
The MG24Quake repository has been updated with the latest modifications.
Conclusions
With this last update we have removed one limitation on our Quake port: the retail version can now run as well, using the same amount of RAM. This of course required to use larger flash ICs, to accommodate the larger data files. Increasing the external flash was not the only task. More optimization was needed regarding internal flash and RAM. This gave us the opportunity of increasing the performance in some levels (especially shareware ones), where there was a noticeable amount of unused internal flash or RAM, by caching some alias model skins and copying the colormap to the unused Zone memory.
There are still some limitations, such as lack of multiplayer or music support. Still, this might require too much RAM.
[1] You might wonder how we could initially afford a bigger buffer. This was due to the fact that we first focused in porting the renderer, which runs also when playing demo. At that time, the server part was not running. This means we needed a smaller amount of zone memory.